Механизм полнотекстового поиска
Основные возможности полнотекстового поиска
- поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ);
- поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами);
- возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости;
- возможность указания области выполнения поиска по выбранным объектам метаданных;
- представление результатов поиска в формате XML и HTML с выделением найденных слов;
- полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т.д.) на всех языках конфигурации;
- выполнение поиска с учетом синонимов русского, английского и украинского языков;
- морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ 1С:Предприятие;
- возможность использования дополнительных словарей полнотекстового поиска;
- в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, предоставленные компанией "Информатик".
Полнотекстовый поиск в базе данных
Механизм полнотекстового поиска в данных системы 1С:Предприятие 8 позволяет осуществлять поиск в базе данных с указанием поисковых операторов (И, ИЛИ, НЕ, РЯДОМ и др.).
Механизм полнотекстового поиска основан на использовании двух составляющих:
- полнотекстового индекса, который создается для текущей базы данных и затем периодически, по мере необходимости, обновляется;
- средств выполнения полнотекстового поиска.
Создание и обновление полнотекстового индекса может быть выполнено интерактивно, в режиме 1С:Предприятие 8, или программно, средствами встроенного языка. Ниже приведен диалог управления полнотекстовым индексированием в режиме 1С:Предприятие:
Для выполнения поиска данных в базе данных может использоваться, например, обработка Поиск данных, представленная ниже.
В представленном примере найдены документы, реквизиты которых содержат значения, начинающиеся на "Компл" и "вент" - контрагент "Комплетк ТД" и реквизиты, содержащие различные формы слова "вентилятор".
Система 1С:Предприятие 8 позволяет осуществлять выборочное включение данных прикладных объектов и их реквизитов в полнотекстовый поиск. Также существует возможность ограничить область поиска данными только указанных объектов конфигурации.
Полнотекстовый поиск в справочной системе
В справочной системе 1С:Предприятия 8 также реализован полнотекстовый поиск, позволяющий использовать поисковые операторы И, ИЛИ, НЕ, РЯДОМ и др.. При этом найденные слова выделяются.
Программный интерфейс
Используются следующие прикладные объекты:
- МенеджерПолнотекстовогоПоиска
- СписокПолнотекстовогоПоиска
- ЭлементСпискаПолнотекстовогоПоиска
МенеджерПолнотекстовогоПоиска имеет методы для построения индекса поиска, проверки его актуальности, а также создания списка поиска типа СписокПолнотекстовогоПоиска по заданному запросу.
МенеджерПолнотекстовогоПоиска доступен как свойство глобального контекста ПолнотекстовыйПоиск.
СписокПолнотекстовогоПоиска предоставляет доступ к результатам поиска. Кроме того, можно указать область поиска в виде массива элементов метаданных конфигурации.
Результатом поиска является ЭлементСпискаПолнотекстовогоПоиска.
Операторы строки поиска
В строке ввода допускается использование следующих поисковых операторов:
И (AND или #) - поиск данных, содержащих все слова; пример: "запись И документ" - в реквизитах должны быть и "проведение" и "документ" (с учетом морфологии);
ИЛИ (OR или | или,) - поиск хотя бы одного слова из перечисленных; пример: "запись ИЛИ документ" - в реквизитах должно быть хотя бы одно из слов "запись" или "документ";
НЕ (NOT или ~) - поиск данных, в реквизитах которых есть первое слово, но нет второго; пример: "закрытие НЕ месяц" - будут найдены все, содержащие "закрытие", но не содержащие слова "месяц". Использование "~" в начале строки не допускается;
РЯДОМ/n (NEAR/[+/-]n) - поиск данных, содержащих в одном реквизите указанные слова с учетом морфологии на расстоянии n слов между словами.
Знак указывает, в каком направлении от первого слова будет искаться второе слово ("+" – после первого; "-" – до первого слова).
Если знак не указан, то будет найдены данные, содержащие указанные слова на дистанции n слов друг о друга.
Порядок слов не имеет значения.
- "фен РЯДОМ/3 воздух" - будут найдены данные, в которых "воздух" находится не более 3-х слов до или после "фен";
- фен РЯДОМ/+3 воздух - будут найдены данные, в которых "воздух" находится не более 3-х слов после "фен";
- фен РЯДОМ/-3 воздух - будут найдены данные, в которых "воздух" находится не более 3-х слов перед "фен".
РЯДОМ(NEAR) - упрощенный оператор дистанции: оба слова расположены не далее, чем в 8-ми словах друг от друга; пример: "проведение РЯДОМ документ";
"" (текст в кавычках) - поиск точной с учетом морфологии фразы, пример: "проведение документа" - эквивалентно: проведение /1 документа;
() - группировка слов (сколько угодно уровней вложенности); пример: "(проведение | выписка) # (счета, документа)";
* - поиск с использованием группового символа (замена окончания слова). Должно быть введено более 1 значащего символа; пример: "доку*" - найдет "документ", "документировать", "документальный" и др.;
# - нечеткий поиск слов с заданным количеством отличий от указанного (если не указано, то = 1); пример: запрос "#Система" найдет "систама", "сивтема"; запрос "Система#2" найдет "ситтама", "сеттема";
Поиск с учетом синонимов русского, английского и украинского языков. "!" ставится перед соответствующим словом; пример: поиск "!красный кафель", найдет еще и "алый кафель" и "коралловый кафель".
Если не указано никаких операторов (слова набраны через пробел), то программа осуществляет поиск всех слов из запроса с использованием оператора И.
Примеры
МассивМД = Новый Массив(); МассивМД.Добавить(Метаданные.Справочники.Товары); МассивМД.Добавить(Метаданные.Документы.КассовыйЧек);
СписокПоиска.ОбластьПоиска = МассивМД; СписокПоиска.СтрокаПоиска = ПолеВводаПоиска; СписокПоиска.РазмерПорции = РазмерПорции; СписокПоиска.ПерваяЧасть();
Если СписокПоиска.ПолноеКоличество() = 0 Тогда Если СписокПоиска.СлишкомМногоРезультатов() Тогда Предупреждение("Слишком много результатов, уточните запрос."); КонецЕсли; Возврат; КонецЕсли;
Колво = СписокПоиска.ПолноеКоличество();
СтрHTML = СписокПоиска.ПолучитьОтображение(ВидОтображенияПолнотекстовогоПоиска.HTMLТекст); Сообщить(СтрHTML);
Для каждого индекс=0 По СписокПоиска.Количество-1 Цикл элемент = СписокПоиска.Получить(индекс); Сообщить(элемент.Представление); КонецЦикла;
Особенности
Полнотекстовый поиск работает по всему массиву данных, поэтому при использовании надо обязательно пропускать результат через фильтр безопасности.
Например, в мультибазной системе нужно отсекать объекты других баз.
Кроме того, такая фильтрация тесно пересекается с контролем доступа. Известно, что очень часто "дырой" в безопасности являются как раз механизмы поиска.
- Настройка регламентных и фоновых заданий;
- Диагностика и устранение ошибок информационной базы, имеющий файловый формат хранения данных;
- Запустить индексацию полнотекстового поиска в 1С либо выключить его вовсе;
- Запуск базы на последних Платформах 8.3.8;
- Запуск в Тонком Клиенте;
- Увеличение скорости перепроведения документов при отключенном антивирусе;
- Запустить Пересчет итогов и восстановление последовательности;
- Выполнить Тестирование и исправление базы, проверку утилитой chdbfl.exe;
- Если конфигурация не типовая, то есть доработанная программистами под конкретную организацию, выполнить Проверку конфигурации;
- Отключить ненужные функциональные режимы;
- Настроить права пользователей;
- Свертка базы;
- Модернизация аппаратной части.
Способ 1. Настройка регламентных и фоновых заданий
Приложение в новой редакции 1С Бухгалтерия 3.0 помимо выполнения основной работы запускает операции в фоновом режиме, которые ведут к снижению быстродействия программы.
Фоновый режим - это режим ожидания, то есть операция запущена всегда, хоть и не используется.
Шаг 1. Настройка регламентных и фоновых заданий
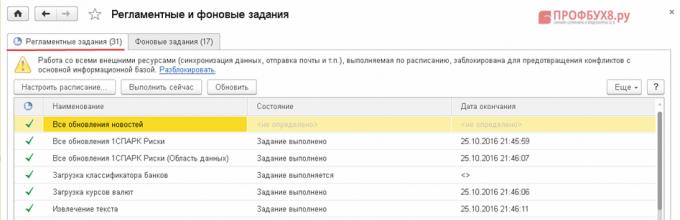
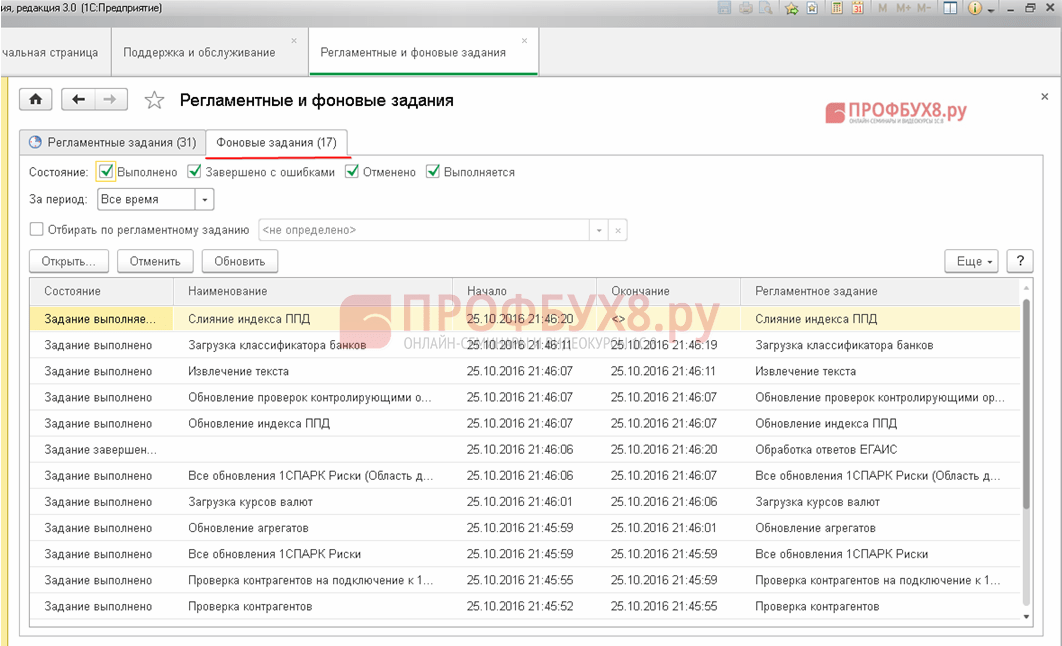
Открываем перечень регламентных и фоновых заданий: раздел Администрирование – Поддержка и обслуживание – Регламентные операции – Регламентные и фоновые задания :
После запуска программы 1С 8.3 автоматически запускаются фоновые задания и выполняются регламентные задачи, которые используют огромное количество ресурсов и замедляют работу программы. Следовательно, нужно проанализировать работу бухгалтеров и определить какие фоновые задачи целесообразно оставить в автозапуске, а какие нужно отключить.
На рисунке видим список регламентных заданий, которые запускаются в 1С 8.3 Бухгалтерия:

На рисунке видим список выполненных фоновых заданий:
Например,
- Программа 1С 8.3 Бухгалтерия для обновления различных классификаторов постоянно подключается к сайту;
- Если на предприятии не ведутся операции связанные с иностранной валютой, то нет необходимости отслеживать курсы валют;
- Если бухгалтер не пользуется полнотекстовым поиском в программе, то не целесообразно запускать процесс «Извлечение текста».
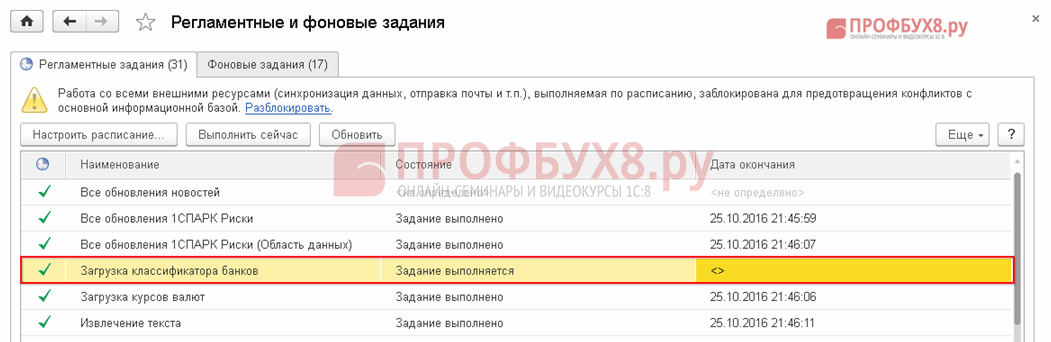
Шаг 2. Отключение нецелесообразных задач
Рассмотрим подробно как отключить загрузку . Установим курсор на нужную строку и сделаем двойной щелчок:
Для отключения задания убираем галочку Включено:

Шаг 3. Настройка расписания регламентных задач
Рассмотрим подробно, как настроить расписание . Установим курсор на нужную строку и сделаем двойной щелчок:

Выберем пункт Расписание:

В открывшемся окне переходим на нужную закладку и делаем соответствующую настройку:

Способ 2. Диагностика и устранение ошибок информационной базы, имеющей файловый формат хранения данных
Шаг 1.
Создаем резервную копию базы данных.
Шаг 2.
Запускаем процедуру . Для этого открываем Конфигуратор и запускаем процедуру Тестирование и исправления информационной базы: раздел Администрирование – Тестирование и исправление. Выбираем проверки и режимы, которые нужно выполнить для информационной базы:

Рассмотрим, подробнее предлагаемые варианты проверки:
- Реиндексация таблиц информационной базы – перестраивает индексы таблиц для повышения быстродействия работы базы данных;
- Проверка логической целостности информационной базы – проверка логики базы данных;
- Проверка ссылочной целостности информационной базы – проверка логической целостности базы данных для обнаружения «битых» ссылок;
- Пересчет итогов – перерасчет итогов таблиц регистров накопления;
- Сжатие таблиц информационной базы – уменьшает размер базы данных после тестирования и исправления;
- Реструктуризация таблиц информационной базы – оптимизирует структуру базы данных используя вспомогательные файлы с целью повышения стабильности и быстродействия.
Если выбираем вариант процедуры Тестирование и исправление в режиме Проверка ссылочной целостности информационной базы, то пункты настроек по обработке ошибок базы данных становятся доступными:
- Пункт При наличии ссылок на несуществующие объекты означает, что при обнаружении «битых» ссылок, будет обрабатывать ссылки, используя выбранный вариант;
- Пункт При частичной потере данных объектов означает, что остаток данных достаточен для восстановления данных какого-либо объекта.
Процедуру тестирования и исправления информационной базы 1С можно выполнять только в монопольном режиме.
Способ 3. Запустить индексацию полнотекстового поиска в 1С либо выключить его вовсе
Полнотекстовый поиск данных компания 1С разработала для облегчения поиска незнакомой информации пользователем. Особенностью полнотекстового поиска данных в 1С 8.3 является:
- Пользователь может вводить поисковый запрос в простой форме и использовать специальные операторы, такие как: и, или, не .
- Полнотекстовый поиск данных работает с полями типа ХранилищеЗначения и с длинными текстовыми полями, при этом пользователю не будут показаны результаты на которых у него нет прав.
Например, нужно настроить полнотекстовый поиск в документах Авансовый отчет.
Шаг 1.
Шаг 2.
Открываем документ Авансовый отчет: меню Конфигуратор – Открыть конфигурацию.
Шаг 3.
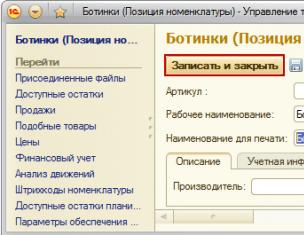
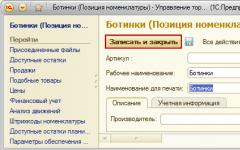
В строке Полнотекстовый поиск выбираем пункт Использовать: Авансовый отчет – Поле ввода – Полнотекстовый поиск:

Шаг 4.
Запускаем программу и обновляем режим полнотекстового поиска. Открываем Регламентные операции: раздел Администрирование – Настройки программы – Поддержка и обслуживание:
Шаг 5.
Открываем настройку и обновляем индекс используя кнопку Обновить индекс:

Способ 4. Запуск базы на последних платформах 8.3.8
Как обновить технологическую платформу 1С 8.3 смотрите в нашем видео уроке:
Специалисты 1С улучшили распределение нагрузки:
- Имеется возможность более точно управлять объемом памяти, расходуемой рабочими процессами сервера, что позволяет повысить устойчивость кластера к неосторожным действиям пользователей.
- Реструктуризация информационных баз в фоновом режиме. Новая возможность позволяет свести к минимуму время простоя системы, необходимое для обновления прикладных решений.
- Платформа версии 8.3 получила новый интерфейс приложений “Такси”, более удобный и наглядный с новым ярким дизайном. Улучшились возможности навигации по приложению. Пользователь может самостоятельно настраивать свое рабочее пространство, располагая панели в разных областях экрана. Новый механизм ввода по строке существенно ускоряет поиск данных. Подробнее о новых возможностях программы 1С 8.3 Бухгалтерия интерфейс “Такси” смотрите в нашем видео:
Способ 5. Запуск в Тонком клиенте
Работа в режиме тонкого клиента возможна только в режиме управляемого приложения. В режиме тонкого клиента все действия выполняются на сервере, пользователю выводиться лишь отображение получаемой информации. Этот режим работы не требует больших ресурсов как системы, так и канала связи.
Способ 6. Поменять антивирусное программное обеспечение
Если стоит антивирус Avast или Касперский, то желательно заменить на другой. Опыт показал увеличение скорости перепроведения документов при отключенном антивирусе в разы, так как антивирусы занимают ресурсы компьютера.
Способ 7. Тестирование и исправление базы, проверка утилитой chdbfl.exe
Необходимо выполнить Тестирование и исправление базы, предварительно сделав копию.
Шаг 1. Делаем копию базы данных
Как сделать резервную копию 1С 8.3 смотрите в следующем видео уроке:
Шаг 2. Выполняем проверку с помощью утилиты chdbfl.exe
Утилиту chdbfl.exe используют в случаях, когда система не запускается даже в режиме конфигуратора. Расположена утилита в папке «bin» установленной технологической платформы, например: c:\Program Files (x86)\1cv8\8.3.9.1818\bin\chdbfl.exe:

Выполняем проверку с помощью утилиты chdbfl.exe:

Шаг 3. Выполнить Тестирование и исправление базы
Выполнить Тестирование и исправление базы запустив систему в режиме конфигуратора.
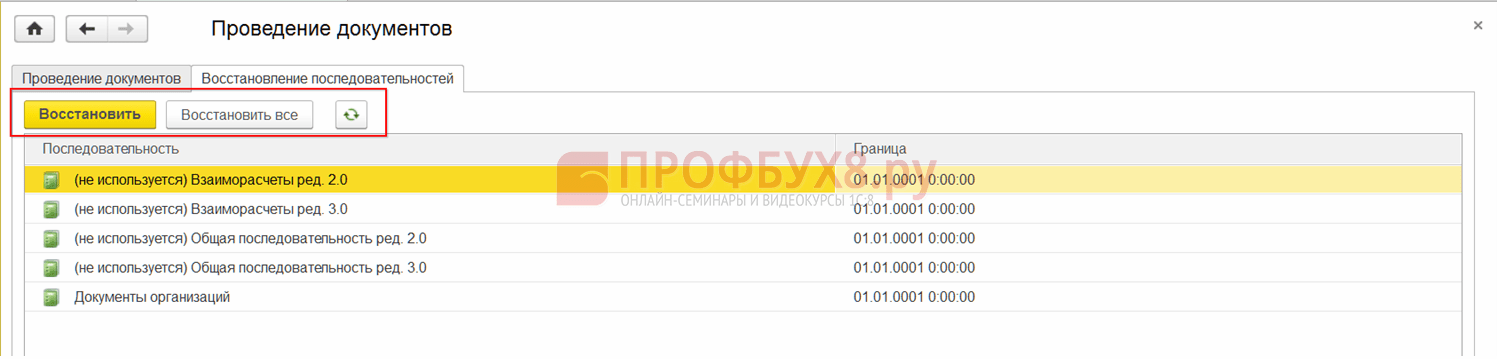
Шаг 4. Восстановление последовательности документов
Для восстановления последовательности в 1С 8.3 открываем Все функции: главное Меню – Все функции. Выбираем нужный пункт и открываем используя кнопку Открыть:

В открывшемся окне на закладке Восстановление последовательностей и нажимаем Восстановить или Восстановить все:
Способ 8. Если конфигурация не типовая, то выполнить проверку конфигурации
Если конфигурация не типовая, то есть доработанная программистами под конкретную организацию, то выполняем проверку конфигурации.
Шаг 1.
Запускаем программу в режиме Конфигуратор.
Шаг 2.
Открыть конфигурацию БД: раздел Конфигурация – Конфигурация базы данных:

Шаг 3.
Выбираем пункт Проверка конфигурации и делаем настройки:

Способ 9. Отключить ненужные функциональные режимы
Открываем Функциональность программы 1С 8.3: раздел Главное – Настройки – Функциональность, делаем настройки по каждому разделу:

Способ 10. Настроить права пользователей
Шаг 1.
Запускаем 1С 8.3 в режиме Конфигуратор.
Шаг 2.
Открываем список пользователей: раздел Администрирование – Пользователи. На закладке Прочее определяем какие роли нужно назначить пользователю и отметить их галочкой.
Уменьшение выбранного функционала уменьшает время на отсортировку программой управляемых форм при открытии списка документов, то есть чем меньше лишнего в управляемом интерфейсе – тем быстрее он работает:

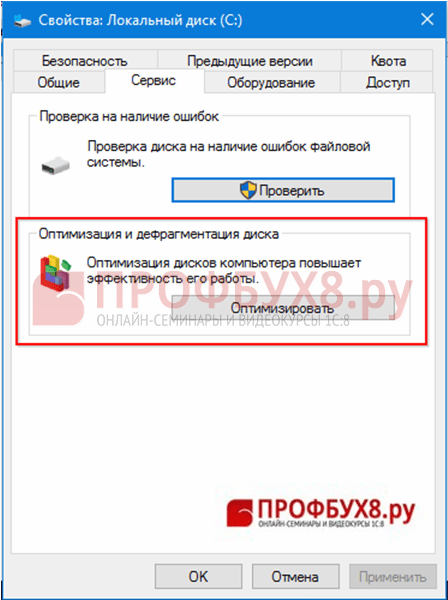
Способ 11. Дефрагментация диска с файловой базой
Процедура дефрагментация диска производит оптимизацию файлов находящихся на жестком диске для увеличения скорости работы системы. Дефрагментацию нужно делать только при необходимости, так как увеличивает процесс износа диска.
Выделив жесткий диск, правой клавишей мыши вызываем команду Свойства:

На закладке Сервис выбираем Оптимизация и дефрагментация диска:
Способ 12. Свертка базы
– это ввод актуальных остатков на определенную дату и удаление старых, ненужных документов. Этот способ может оказаться полезным, если база большого объема, например, за несколько лет. Свертку необходимо производить без работающих в системе пользователей.
Шаг 1. Создаем копию базы данных
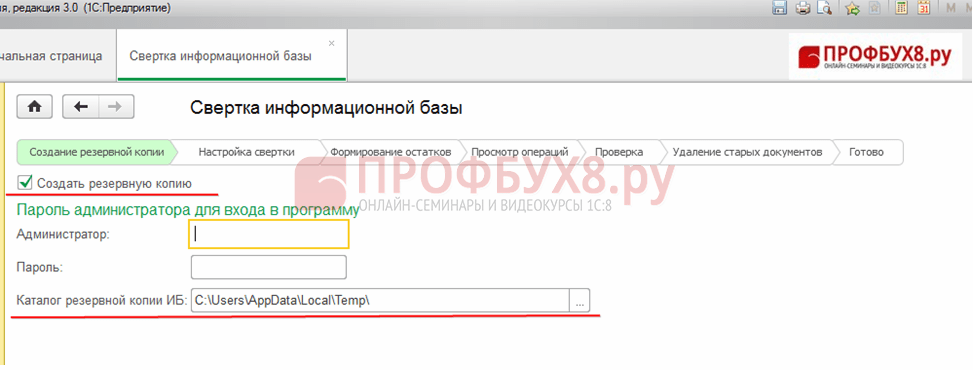
Шаг 2. Выполняем процедуру свертки базы 1С 8.3
Раздел Администрирование – Сервис – Свертка информационной базы.
На первом этапе программа 1С 8.3 предлагает сделать резервную копию, где нужно указать каталог для сохранения. Нажимаем Далее:
До сих пор немногие знают, что, начиная с версии 8.1, у платформы "1С:Предприятие" появился замечательный и очень полезный механизм - полнотекстовый поиск. Что это такое? Чем он может оказаться полезен именно вам? На эти вопросы в статье отвечает В.В. Рыбалка, фирма "1С".
Для начала несколько слов о том, что же это за механизм. Полнотекстовый поиск, говоря простым языком, позволит найти текстовую информацию, размещенную практически в любом месте используемой конфигурации. При этом искать нужные данные можно либо по всей конфигурации в целом, либо сузив область поиска до нескольких объектов (например, определенных видов документов или справочников). Сами критерии поиска могут варьироваться в довольно широком диапазоне. То есть найти нужные данные можно, даже не помня точно, где они хранятся в конфигурации и как именно записаны.
Полнотекстовый поиск предоставляет следующие возможности.
- Есть поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ 7.79-2000). Пример: "русская фраза" = "russkaya fraza".
- Есть поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами). Пример: "руссrfz фраpf" (окончания каждого слова набраны латиницей, допустим, в результате ошибки оператора).
- Есть возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости. Пример: указав в строке поиска слово "привет" и нечеткость 17 %, найдем все аналогичные слова с ошибками и без: "привет", "превет", "привед".
- Есть возможность указать область выполнения поиска по выбранным объектам метаданных.
- Полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т. д.) производится на всех языках конфигурации.
- Поиск выполняется с учетом синонимов русского, английского и украинского языков.
- Морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ "1С:Предприятие".
- Стандартно в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, которые предоставлены компанией "Информатик".
- Поиск можно осуществлять с использованием подстановочных символов ("*"), а также с указанием поисковых операторов ("И", "ИЛИ", "НЕ", "РЯДОМ") и спецсимволов.
Полнотекстовый поиск можно осуществлять в любой конфигурации на платформе "1С:Предприятие 8.1".
Это касается и конфигураций, которые были сконвертированы из версии 8.0. Для включения возможностей использования полнотекстового поиска, достаточно зайти в меню "Операции" вашей конфигурации и выбрать пункт "Управление полнотекстовым поиском", после чего включить эту возможность (см. рис. 1).
Рис. 1
Если вы используете типовые конфигурации на платформе 8.1, то, скорее всего, в них уже встроена обработка "Поиск данных" (меню "Сервис"/"Поиск данных"). Если же такая обработка отсутствует в используемой конфигурации, не беда.
Ее всегда можно найти на диске ИТС. В этой статье мы будем использовать для демонстрации возможностей полнотекстового поиска примеры работы именно этой обработки в демонстрационной конфигурации "Бухгалтерия предприятия" (ред. 1.6).
Как уже было сказано, поиск может осуществляться по нескольким словам, с использованием поисковых операторов и по точной фразе. Кроме того, место поиска можно ограничивать конкретными объектами конфигурации (например, документы "Акт об оказании производственных услуг") или списком/набором объектов конфигурации.
При поиске данных допускается использование поисковых операторов в строке поиска (все операторы необходимо указывать только ЗАГЛАВНЫМИ буквами и без кавычек), указанных в таблице.
Таблица

Имейте ввиду: если не указаны никакие операторы (слова набраны через пробел), программа осуществляет поиск всех слов из запроса с использованием оператора "И".
Рис. 2 демонстрирует пример простого поиска по части слова. Набрав "надеж*", мы получили в результате ссылку на физическое лицо, а также на документы, в комментариях которых встречается фраза "Надежный клиент".

Рис. 2
Рис. 3 демонстрирует пример более сложного поиска с использованием конструкции "ИЛИ" в строке поиска и ограничения области поиска по справочнику "Номенклатура" и документам "Поступление товаров и услуг", "Реализация товаров и услуг". Наглядно видно, что поиск отразил всю номенклатуру, в названиях которой присутствует либо слово "чайник", либо слово "BINATONE", а также все документы указанных видов, содержащие всю подходящую номенклатуру.

3.4.9 полнотекстовый поиск: Автоматизированный документальный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста (англ. Full text searching , фр. Recherche en texte integral )
Полнотекстовый индекс
Первые версии программ полнотекстового поиска предполагали сканирование всего содержимого всех документов в поиске заданного слова или фразы. При использовании такой технологии поиск занимал очень много времени (в зависимости от размера базы), а в интернете был бы невыполним. Современные алгоритмы заранее формируют для поиска так называемый полнотекстовый индекс - словарь, в котором перечислены все слова и указано, в каких местах они встречаются. При наличии такого индекса достаточно осуществить поиск нужных слов в нём и тогда сразу же будет получен список документов, в которых они встречаются.
Примечания
См. также
Wikimedia Foundation . 2010 .
Смотреть что такое "Полнотекстовый поиск" в других словарях:
Автоматизированный информационный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста. По английски: Full text searching См. также: Автоматизированный информационный поиск… … Финансовый словарь
полнотекстовый поиск - Автоматизированный документальный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста. [ГОСТ 7.73 96 ] Тематики поиск и распространение информации Обобщающие термины информационный … Справочник технического переводчика
полнотекстовый поиск - 3.4.9 полнотекстовый поиск: Автоматизированный документальный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста en Full text searching fr Recherche en texte integral Источник …
полнотекстовый поиск - Rus: полнотекстовый поиск Eng: full text searching Fra: recherche en texte integral Автоматизированный документальный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста. ГОСТ 7.73 … Словарь по информации, библиотечному и издательскому делу
ПОЛНОТЕКСТОВЫЙ ПОИСК - согласно ГОСТ 7.73–96 «Поиск и распространение информации. Термины и определения», – автоматизированный документальный поиск, при котором в качестве поискового образа документа используется его полный текст или существенные части текста … Делопроизводство и архивное дело в терминах и определениях
Поиск данных раздел информатики, изучающий алгоритмы для поиска и обработки информации как в структурированных (см. напр. базы данных) так и неструктурированных (напр., текстовый документ) данных. Поиск данных неразрывно связан с понятием… … Википедия
Информационный поиск (ИП) (англ. Information retrieval) процесс поиска неструктурированной документальной информации и наука об этом поиске. Содержание 1 История 2 Информационный поиск как процесс … Википедия
- (англ. Information retrieval) процесс поиска неструктурированной документальной информации, удовлетворяющей информационные потребности (англ.)русск., и наука об этом поиске … Википедия
ГОСТ 7.73-96: Система стандартов по информации, библиотечному и издательскому делу. Поиск и распространение информации. Термины и определения - Терминология ГОСТ 7.73 96: Система стандартов по информации, библиотечному и издательскому делу. Поиск и распространение информации. Термины и определения оригинал документа: 3.2.5 автоматизированная информационно поисковая система: ИПС,… … Словарь-справочник терминов нормативно-технической документации
Книги
- История Византии. Хрестоматия. Часть 2. Исторические документы и исследования (DVD) , Мартов Владимир , Издательство "Директмедиа Паблишинг" выпускает новую серию "Клио", представляющую собой ряд изданий по всемирной истории. Открывают серию хрестоматии по истории Византии - "Историки Византии"… Категория: История. Мультимедиа Издатель:
Многие СУБД поддерживают методы полнотекстового поиска (Fulltext search), которые позволяют очень быстро находить нужную информацию в больших объемах текста.
В отличие от оператора LIKE, такой тип поиска предусматривает создание соответствующего полнотекстового индекса, который представляет собой своеобразный словарь упоминаний слов в полях. Под словом обычно понимается совокупность из не менее 3-х не пробельных символов (но это может быть изменено). В зависимости от данных словаря может быть вычислена релевантность – сравнительная мера соответствия запроса найденной информации.
В статье рассказывается как работать с полнотекстовым поиском на примере БД MySQL, а так же приведу примеры «нестандартного» использования данного механизма.
В MySQL возможности полнотекстового поиска (только для MyISAM-таблиц) поддерживаются начиная с версии 3.23.23. В последующих версиях механизм потерпел существенные доработки и расширения, в тоге превратившись в мощное средство для создания поисковых механизмов веб-приложений. Главная особенность – быстрый поиск слов в очень больших объемах текстовой информации.
Индекс FULLTEXT
Итак, чтобы работать с полнотекстовым поиском, сначала нам нужно создать соответствующий индекс. Он называется FULLTEXT , и может быть наложен на поля CHAR, VARCHAR и TEXT. Причем, как и в случае с обычным индексом – если происходит поиск по 2-м полям, то нужен объединенный индекс 2-х полей, используйте поиск по одному полю – нужен индекс только этого поля. Например:CREATE TABLE `articles` (
`id` int(10) unsigned NOT NULL auto_increment,
`title` varchar(200) default NULL,
`body` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `ft1` (`title`,`body`),
FULLTEXT KEY `ft2` (`body`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
В этом примере создается таблица с 2-мя полнотекстовыми индексами: ft1 и ft2 , которые можно использовать для поиска в полях title и body , или только в body . Только в поле title искать не получится.
Конструкция MATCH-AGAINST
Собственно для самого полнотекстового поиска в MySQL используется конструкция MATCH(filelds)… AGAINST(words) . Она может работать в различных режимах, которые достаточно сильно между собой отличаются. Для всех действует следующее правило: данная конструкция возвращает условную релевантность, но способ вычисления которой может быть разным в зависимости от режима. Еще стоит добавить что во всех режимах поиск всегда регистрозависимый. Далее более подробно о каждом из них.MATCH-AGAINST IN NATURAL LANGUAGE MODE
- это основной вид поиска, который используется по умолчанию, т.е. если режим не указан:SELECT * FROM `articles` WHERE MATCH (title,body) AGAINST ("database");
В этом примере мы ищем слово database в полях title и body таблицы articles на основе индекса ft1 (см. пример создания таблицы выше). Выборка будет автоматически отсортирована по релевантности – это происходит в случае указания конструкции MATCH-AGAINST внутри блока WHERE и не задано условие сортировки ORDER BY.
Кстати, несмотря на возможности алиасов, при запросах конструкцию приходится повторять в разных местах, что усложняет запросы. Вот например нельзя написать так:
FROM `articles`
WHERE REL > 0;
Этот запрос выдаст ошибку: поле Rel не определено . Что бы работало, придется продублировать данную конструкцию:
SELECT *, MATCH (title,body) AGAINST ("database") as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ("database") > 0;
Однако, сколько бы вы не использовали одну и туже конструкцию (разумеется с одинаковыми параметрами) она будет вычислена только один раз .
В примере выше в переменной REL будет вычислена релевантность. Эта величина зависит прежде всего от количества слов в полях tilte и body , того насколько близко данное слово встречается к началу текста, отношения количества встретившихся слов к количеству всех слов в поле и др.
Например, релевантность будет не нулевая, если слово database встретится либо в title , либо body , но если оно встретится и там и там, значение релевантности будет выше, нежели если оно два раза встретится в body .
Сама по себе релевантность ничего не определяет. Это лишь сравнительная характеристика, по которой можно сортировать результат выборки, не более того.
Еще следует заметить что для IN NATURAL LANGUAGE MODE действует так называемое «50% threshold» . Это означает, что если слово встречается более чем в 50% всех просматриваемых полей, то оно не будет учитываться, и поиск по этому слову не даст результатов.
MATCH-AGAINST IN BOOLEAN MODE
В бинарном режиме, в отличие от других режимов, релевантность вычисляется несколько иначе - как условная мера совпадения заданного шаблона. Положение искомого шаблона в тексте, количество встретившихся вариантов роли не играют.Самая важная особенность бинарного режима – возможность указания логических операторов . Сами операторы я приводить не буду, о них хорошо рассказано в оригинальной документации по MySQL .
Еще особенностями бинарного режима является отсутствие автоматической сортировки в случае указания условия WHERE, однако для сортировки можно использовать алиас:
SELECT *,
MATCH (title,body) AGAINST ("+database MySQL" IN BOOLEAN MODE) as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ("+database MySQL" IN BOOLEAN MODE)
ORDER BY REL;
Пример выведет все записи содержащие слово database , но если в записи присутствует слово MySQL , то его релевантность будет выше. Записи будут отсортированы по релевантности.
В бинарном режиме отсутствует ограничение «50% threshold» . Бинарный режим можно использовать и без создания полнотекстового индекса, однако это будет работать очень медленно.
MATCH-AGAINST IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
Или просто «WITH QUERY EXPANSION» . Работает примерно также, как NATURAL LANGUAGE MODE, с той лишь разницей, то в результат поиска попадают не только совпадения с шаблоном, но и возможные логические совпадения. Это работает примерно так:Сначала MySQL выполняет запрос аналогичный NATURAL LANGUAGE MODE и формирует результат. По этому результату производится попытка вычислить слова, которые так же имеют высокую релевантность для полученной выборки. В случае, если эти слова присутствуют производится поиск и по ним тоже, но значение их на релевантность будет существенно ниже. Отдается смешанная выборка – сначала те результаты, где слово присутствует, а потом те, которые были получены в результате «повторного» поиска.
Использование FULLTEXT SEARCH
Пара слов об алгоритмах поиска
Ну, конечно полнотекстовый поиск можно использовать прежде всего для написания алгоритмов поиска. :-) Я не буду заострять на них внимание, скажу просто что при индексации текстовой информации может понадобиться сложный алгоритм обработки, например такой:- убрать все HTML-теги
- убрать все непечатные символы, знаки препинания и тому подобное
- убрать все слова длинной менее 3-х символов
- перевести все слова в нижний регистр
Соответственно, с поисковым запросом надо сделать тоже самое. Режим поиска используется любой – как удобнее… А вообще поиск – это отдельная тема, про которую нужна отдельная статья.
Раскрытие связок многое-ко-многим
В некоторых случаях – не во всех – с помощью полнотекстового поиска можно раскрывать соотношения многое-ко-многим без привлечения третьей таблицы.Допустим, у нас есть две большие таблицы: с пользователями и группами пользователей . Причем, каждый пользователь имеет отношение к большому количеству различных групп, в свою очередь группы включают в себя большое количество пользователей. При нормальном соотношении (т.е. раскрытии через 3-ю таблицу), что бы выбрать все группы, которые принадлежат к некоторому пользователю понадобиться сделать запрос, объединяющий 2 или 3 таблицы, что даже при присутствии индексов очень накладно.
Однако можно выполнить денормализацию по следующей схеме:
Теперь, что бы выбрать группы, принадлежащие к пользователю 2 можно сделать:
SELECT *
FROM `groups`
WHERE MATCH (groups) AGAINST ("+user2" IN BOOLEAN MODE);
Это будет работать намного быстрее, чем исходный вариант (с 3-ей таблицей). Аналогично с группами, но если подобные выборки нам в принципе не нужны, то можно обойтись без соответствующего поля в таблице групп. Тогда получится что-то вроде «односторонней» связи M:N. То есть можно вычислить все M, которые принадлежат к N, не нельзя сделать обратного.
В этом случае, как правило, используется IN BOOLEAN MODE.
- Кстати, на эту схему очень хорошо ложится тегирование информации, но там не все так просто и это опять же отдельная тема.
Использование релевантности как меры отношения одного объекта к другому
Один из алгоритмов для вычисления статей, «похожих» на данную статью . Всё просто: берутся теги данной статьи, и делается полнотекстовый запрос по полю с тегами всех остальных статей с сортировкой по релевантности (если она нужна). Естественно, сначала вылезут те, которые содержат максимальное совпадение по тегам.Можно и без учета тегов. Если статьи индексированы для полнотекстового поиска, из индекса выбираются с десяток наиболее употребляемых слов, после чего делается поиск по ним.
Или вот еще пример – интересы пользователей. Используя точно такую же схему можно легко найти других пользователей, у которых интересы наиболее соответствуют вашим.